Automated Build Systems and Their Limitations
An introduction to traditional build tools like Makefiles and IDE projects, highlighting the maintenance, scalability, and cross-platform challenges that result
In the last two lessons, we've wrestled with the command line. We've compiled, linked, and managed dependencies using a flurry of flags like -I, -L, and -l. We've seen that while this is possible for a tiny project, it's a completely untenable way to build real software. No sane developer types out a 20-file g++ command every time they want to build.
To escape this tedium, we turn to build systems. A build system is a tool that automates the process of compiling and linking. You tell it what to build, and it figures out how to call the compiler and linker with the correct commands and flags.
Before we crown CMake as our champion, it's useful to understand the tools it was designed to replace. In this lesson, we'll take a tour of the "old ways": manual build tools like Makefiles and the project files generated by IDEs.
These tools are still widely used in industry, particularly in projects that have been around for a long time, so this knowledge is directly useful. Additionally, by understanding their limitations, you'll gain a much deeper understanding of the problems CMake solves.
Build Automation
The most basic form of build automation involves writing a script that contains the exact compiler commands you want to run. The two most common approaches are using make and relying on an IDE's native project format.
Using make and Makefiles
The make utility is a classic build automation tool that has been a cornerstone of Unix development for decades. It reads its instructions from a file, by default named Makefile.
We won't cover make in detail in this course, but have included an example below. A simple project with two source files, and a minimalist Makefile to automate the build process, would look something like this:
Files
To build our project, we just run make:
makeNow, make will handle the compiler interaction for us:
g++ -std=c++20 main.cpp math.cpp -o my_appThis is a huge improvement, and scales much better to larger projects - no more huge terminal commands filled with -l, -L, -i, and other cryptic flags.
Even better, if we run it again without changing anything, it's smart enough to not recompile anything unnecessarily:
makemake: 'my_app' is up to date.In more complex projects involving multiple targets, such as a collection of libraries and a main executable, make is smart enough to only recompile the libraries whose source files we changed since the last build.
IDE Project Files (.sln, .xcodeproj)
The other common approach is to let an IDE handle everything. When you create a project in Visual Studio, it creates a Solution file (.sln) and one or more Project files (.vcxproj). Xcode does the same with .xcodeproj bundles.
These files are the IDE's internal "Makefile." They store all the information about your source files, compiler settings, linker flags, and dependencies.
For example, when you add a new file to the project in the IDE's Solution Explorer or update the include directories within your project settings, the IDE updates the .vcxproj file to keep track of these configurations.
When it comes time to compile our project, Microsoft's compiler, msbuild.exe, reads the contents of these .vcxproj files and behaves accordingly.
This is incredibly convenient, especially for beginners. The maintenance of the build script is handled automatically by the IDE's user interface. However, this convenience comes at a cost:
- Opacity: The project files are complex, verbose XML files not meant for human editing. All your build settings are hidden behind layers of GUI property pages.
- Vendor Lock-in: The project is now tied to that specific IDE and platform. Everyone working on your project needs to use this same IDE, and you can't easily take a Visual Studio project and build it on Linux.
- Command-Line Hostility: Building an IDE project from a script requires using platform-specific command-line tools like
msbuild.exeon Windows orxcodebuildon macOS, each with its own unique and complex command-line syntax.
Scalability Issues in Large Codebases
As projects grow from a handful of files to hundreds or thousands, the limitations of these manual approaches become critical bottlenecks.
The Unscalable Makefile
In a large codebase, a single Makefile becomes a monolithic, unreadable monster. To cope, developers invent complex systems of recursive make calls, where subdirectories have their own Makefiles. This sounds modular, but is widely considered harmful because it makes it very difficult to get a global view of the dependency tree, leading to incorrect and inefficient builds.
The Makefile itself becomes a piece of arcane software that only one or two "build gurus" on the team understand. Adding a new library or changing a fundamental build setting becomes a high-risk operation that can break the build for everyone. Duplication runs rampant, with similar rules for building different executables or libraries copied and pasted across multiple Makefiles.
The Unscalable IDE Project
Managing a large system with dozens of interdependent libraries within a single IDE solution also becomes unwieldy.
- Merge Conflicts: IDE project files are a nightmare for version control. If two developers add a file in different branches, the resulting merge conflict in the giant XML file is often impossible to resolve manually. The only safe option is often to accept one version and have the other developer re-add their file in the IDE.
- Scattered Settings: The build configuration is scattered across countless property dialogs for each of the dozens of projects in the solution. Want to change a compiler flag across the entire codebase? Get ready for a lot of clicking. There's no single, text-based source of truth for the build.
- Inter-Project Dependencies: Managing dependencies between projects in the solution is done through the GUI. This creates implicit links that are not easily visible or editable in a text format, making it hard to reason about the overall dependency graph.
Multiple Build Configurations
The final challenge is managing different build configurations. Most projects need to manage at least two different build configurations:
- A
Debugbuild should compile with debugging information (using thegflag in GCC/Clang) and no optimizations (using theO0flag), making it easy to step through with a debugger. - A
Releasebuild should be compiled with full optimizations (using theO3flag) and no debug symbols, making it fast and small for shipping to users.
Most projects need to control many more configurations than this, which introduces further complexity that we need to manage.
Configurations in Makefiles
In a Makefile, you might handle this with variables and conditional logic:
# Default to release
CONFIG ?= Release
CXXFLAGS = -std=c++20
ifeq ($(CONFIG),Debug)
CXXFLAGS += -g -O0
else
CXXFLAGS += -O3 -DNDEBUG
endif
# ... rest of the MakefileA developer would then build by specifying the configuration on the command line: make CONFIG=Debug.
This works, but it's clunky. The logic for different configurations is mixed in with the logic for building targets. Furthermore, you can't easily have a debug build and a release build co-exist.
The object files and executables for each configuration will overwrite each other unless you add even more complex logic to the Makefile to put them in separate directories (e.g., build/debug/ and build/release/).
Configurations in IDEs
IDEs handle this much more gracefully. Visual Studio and Xcode have a built-in concept of configurations:
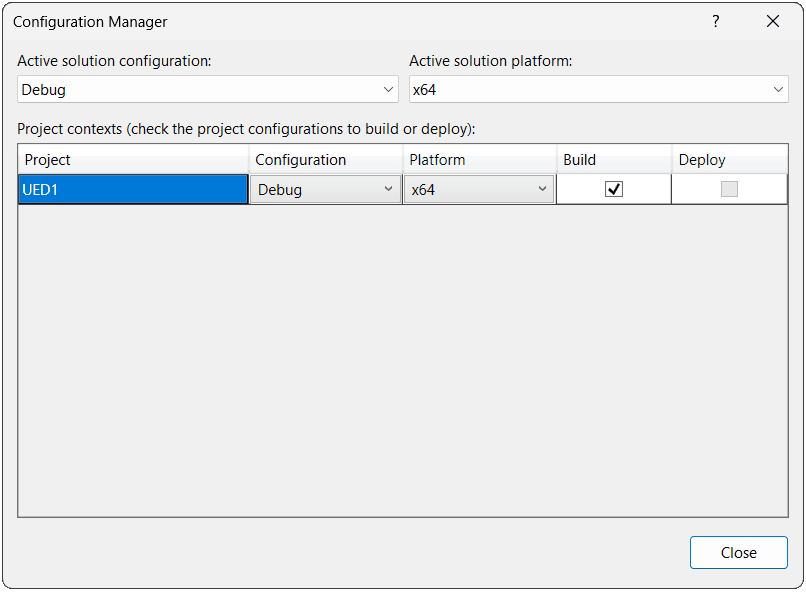
We can then customize each configuration with the set of options we want to be applied when that configuration is selected:
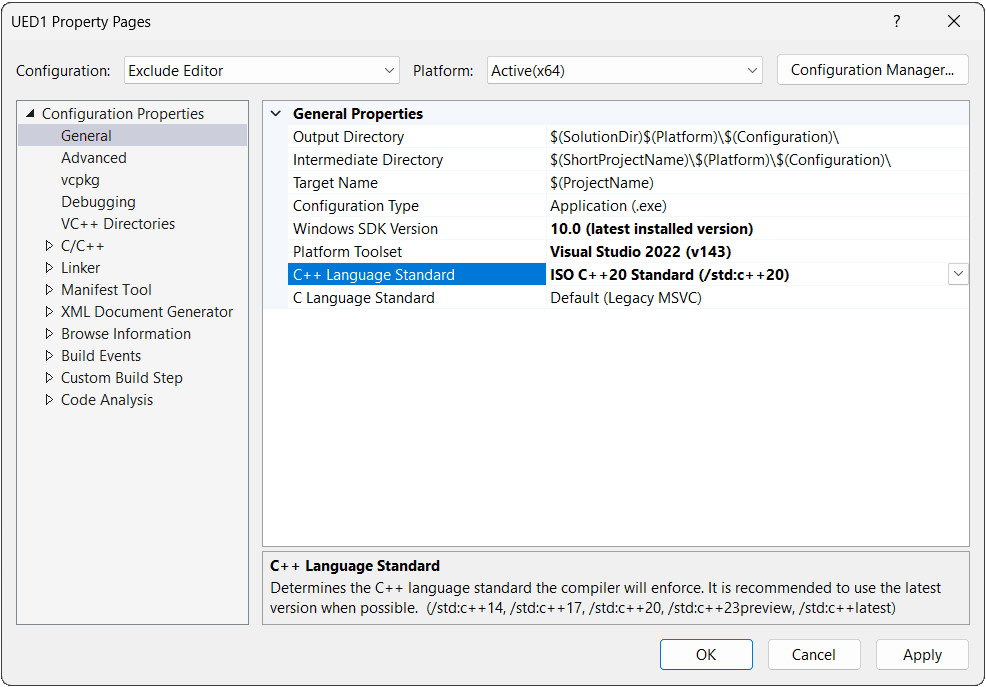
This is a significant advantage over simple Makefiles. However, the configuration settings themselves are still locked away in the GUI and stored in the opaque project files, making them difficult to script, version control, or share consistently across a team.
Why CMake?
An introduction to CMake, the cross-platform, open-source meta-build system that solves the core challenges of C++ project management.