The Compilation Pipeline
Walking through the steps of the C++ compilation process, from source code to machine code.
When we build a C++ program, it isn't a single-step process where source code magically turns into an executable. C++ compilation is a pipeline of stages, each transforming the code closer to machine language.
In this lesson, we'll explore the early stages of that pipeline: taking C++ source and header files through preprocessing, compilation, and assembly to produce object files.
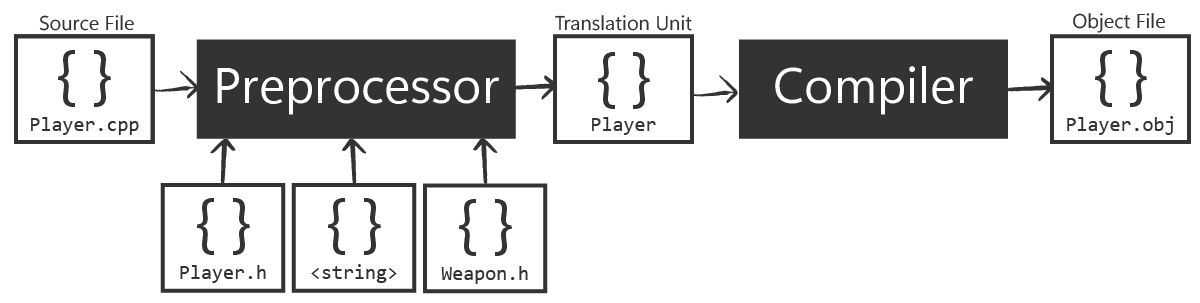
These object files contain the machine code output for our program, and serve as the input for the next stage (linking) to create the final executable.
By understanding this compilation pipeline, you'll gain insight into why we structure C++ projects with header (.h/.hpp) and source (.cpp) files, why certain errors like missing symbols or multiple definitions occur, and how tools like build systems (and later CMake) orchestrate these steps.
We'll cover translation units, macro expansion, include directives, the generation of .obj/.o files, and the role of the assembler in converting human-readable assembly to machine code.
The final linking step, which combines object files into an executable or library, will be discussed in the next lesson.
Note that this lesson is entirely theoretical and relatively advanced. Understanding it is not required to follow along with the rest of the course, so feel free to skip ahead if this is not interesting or doesn't make sense.
Source Files, Headers, and Translation Units
C++ programs are typically spread across multiple files.
- Source files, often with
.cppor.ccextensions, contain function and class definitions - the actual code logic. - Header files, usually with
.hor.hppextensions, typically focus on declarations - interfaces, function prototypes, class definitions without method bodies, constants, etc.
This separation is a long-standing C++ convention that helps organize code and manage compilation dependencies.
We covered and their rationale in a dedicated lesson in our introductory course.
When you compile a C++ program, you usually compile each source file independently. The compiler doesn't immediately know about all parts of your program - it only looks at one source file at a time, plus whatever that source brings in via #include.
This is where the concept of a translation unit comes in. A translation unit is essentially one source file after it has been preprocessed, meaning all the headers it includes are literally inserted and all macros are expanded.
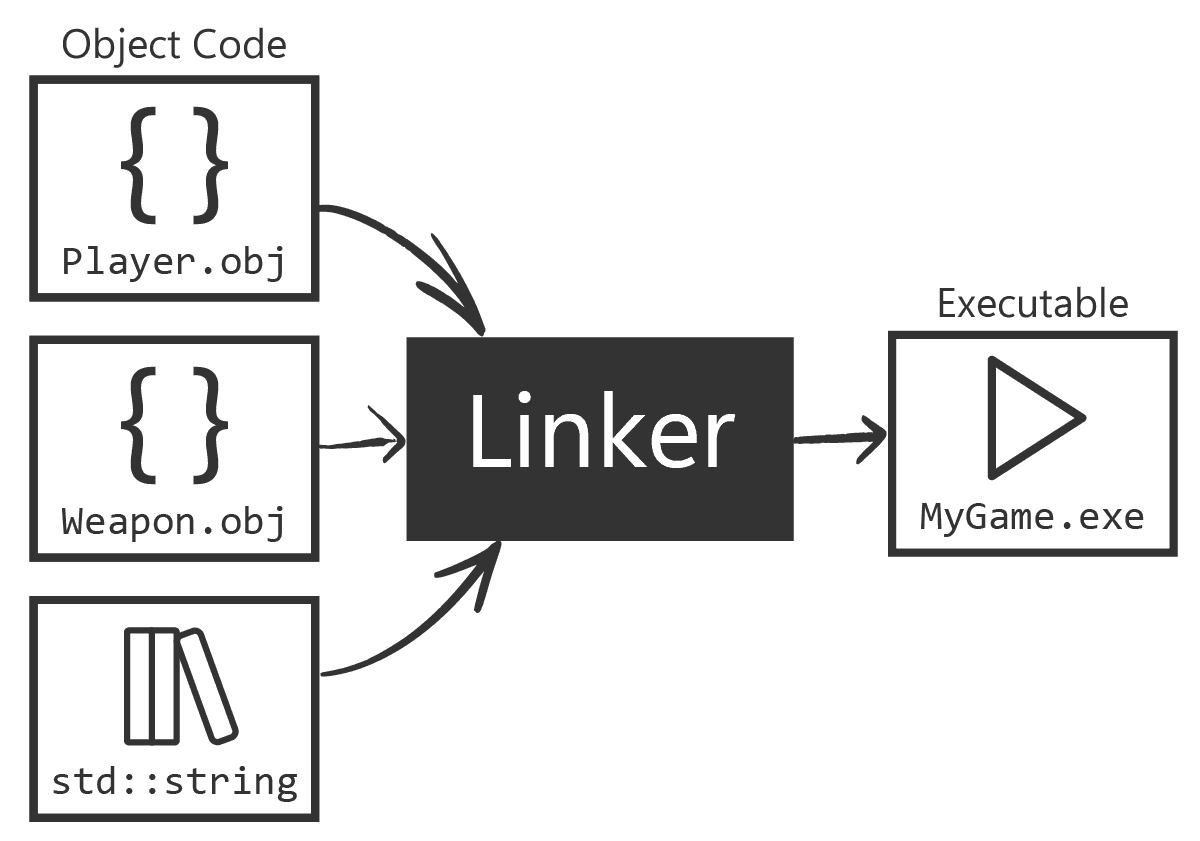
Each source file results in one translation unit and yields one object file when compiled. If you have, say, main.cpp and util.cpp in your project, the compiler will produce something like main.o and util.o separately (or main.obj and util.obj on Windows). It's then the linker's job to combine those object files, but we'll get to that later.
The key point is that the only way code from one file is seen while compiling another is either via an #include directive. are another way but, because they're not yet widely supported or used, we'll ignore those for now.
So, if main.cpp needs something from util.cpp, it must include a header that describes what is in util.cpp. Otherwise, the compiler processing main.cpp has no knowledge of util.cpp's contents. This is why missing includes lead to compile errors like "identifier not found" if you forgot to include a header with a needed declaration.
Preprocessing Stage
The first stage of building a C++ program is preprocessing. The preprocessor is a tool that runs before the compiler's proper analysis of the C++ code.
It works at the textual level, performing simple text substitutions and conditional removals according to directives that start with #. These changes broadly fall into three categories: include resolution, macro expansion, and conditional compilation.
Include Resolution
When it encounters #include <...> or #include "...", it will literally replace that line with the contents of the referenced file, which is usually a header file.
In other words, it pastes the header file's code into the source. This is recursive - if that header includes other headers, those get expanded too. By the end, it's as if you wrote one big file containing your source and all the headers it needs.
For instance, if main.cpp has #include "util.h", the preprocessor will insert everything from util.h into main.cpp's code. It will recursively do the same for any includes inside util.h, and so on.
Macro Expansion
The preprocessor handles #define macros. A macro definition like #define MAX_SIZE 100 tells the preprocessor to replace every occurrence of MAX_SIZE in the code with 100 before compilation. Function-like macros can also take arguments, for example:
#define SQUARE(x) ((x) * (x))
int a = SQUARE(5);Here, the preprocessor will replace SQUARE(5) with ((5) * (5)) wherever it appears.
The compiler never sees SQUARE - by the time we get to actual compilation, that symbol is expanded into its replacement code.
This can lead to pitfalls if not carefully used - e.g., macro expansions don't follow normal function call rules - but that's beyond our scope here.
See the lesson for more about writing macros.
Conditional Compilation
Directives like #if, #ifdef, #ifndef, and #endif let the preprocessor include or exclude parts of code based on conditions.
For instance, you might wrap debug code in #ifdef DEBUG so that it's included only when you define a DEBUG macro. The preprocessor evaluates these conditions and strips out any code in #if blocks that evaluate to false. For example:
#define DEBUG 1
// ...
#if DEBUG
std::cout << "Debug mode\n";
#endifHere, if DEBUG is 1 (true), the line will remain; if we had #define DEBUG 0 or no definition, the std::cout << ... line would be removed entirely from the code seen by the compiler.
After preprocessing, what we have is the translation unit mentioned earlier - a single, combined source file with no #include or #define or #if directives anymore. All those have been acted upon:
- Every included file's contents is present - often many thousands of lines once you include standard headers like
<iostream>. - Every macro is expanded or eliminated.
- Every conditional block is either kept or cut out.
Viewing Preprocessor Output
If you're curious, try running the preprocessor on a small program to see what it produces. Save the following in example.cpp:
example.cpp
#include <iostream>
#define MESSAGE "Hello, world!"
int main() {
#if 0
// This code is excluded by the preprocessor
std::cout << "Debug mode\n";
#endif
std::cout << MESSAGE;
return 0;
}Now run the command (for GCC/Clang):
g++ -E -P example.cpp -o example.iIn this case, -E asks g++ to only run the preprocessor, and -P asks it to exclude line markers from the output. We'll explain line markers soon.
After running the command, we can open example.i in a text editor. We should see that:
- The line
#include <iostream>has been replaced by a huge amount of code - tens of thousands of lines. This is the entire contents of theiostreamheader and all headers it includes. The code we wrote in our original source file will be at the bottom of the file, below all of this stuff. - The macro
MESSAGEis gone, and its occurrences have been replaced with"Hello, world!". - The block under
#if 0is completely removed - it won't appear in the output at all.
This can be an eye-opening experiment to understand how much work the preprocessor does and why the resulting translation unit is often much larger than your initial source file.
Once preprocessing is done, we have our translation unit ready. Now the heavy lifting begins: the compiler will translate this (potentially enormous) code into machine code. That happens in the next stage.
Compilation to Object Code
After preprocessing, the compiler proper takes over. This stage is what we usually think of as "compiling": the compiler reads the preprocessed C++ code - the translation unit - and converts it to machine code instructions.
However, it doesn't immediately make a full program out of it - it produces an object file containing the machine code for just this translation unit.
Object Files
What exactly is an object file? It's a file that contains binary machine code and some extra information needed for later linking. The machine code in an object file corresponds to the functions and code in your source, but if your code calls a function that's defined in another file, the call is left as a placeholder that the linker will fill in.
Think of an object file as "half a puzzle" - it has pieces of the program, but references to other pieces are not resolved yet.
For example, if main.cpp calls a function utilFunc() that's defined in util.cpp, when compiling main.cpp the compiler will include a call instruction to utilFunc but mark it as an external symbol. The actual address for utilFunc isn't known at this point and will be fixed when linking main.o with util.o.
Object files typically have the extension .o on Unix-like systems and .obj on Windows.
They are often in a format like ELF (on Linux/macOS) or COFF/PE (on Windows), which specifies how machine code and data are stored, and includes tables for unresolved symbols - things to link later - and other metadata. You generally don't need to inspect object files directly as they're not meant to be human-readable, but it's useful to know they exist and are the output of the compilation stage.
During this stage, the compiler will perform several tasks:
- Syntax and Semantic Analysis: It checks that the code is valid C++ now that macros have been expanded. It ensures types match, variables are declared, etc.
- Code Generation: It translates C++ constructs to equivalent lower-level operations. For instance, a simple arithmetic operation or a loop gets translated into a sequence of machine instructions that achieve the same effect.
- Optimization: If you have optimization enabled - that is, using
O2orO3flags in GCC/Clang, or default "Release" mode in MSVC - then the compiler will try to improve the machine code. It can do this by removing unused code, inlining functions, unrolling loops, etc. This doesn't change the program's behavior but can make it faster or smaller. - Generate Object File: Finally, the compiler writes out the machine code and data to the object file, along with symbol tables listing things like "this object provides function X" or "this object needs a definition for function Y from elsewhere."
It's at this stage you encounter compile-time errors if something is wrong with your C++ code's structure or rules. For instance, forgetting a semicolon, calling a function with the wrong number of arguments, or violating C++ syntax will cause errors here.
The Assembler and Machine Code
You might wonder how exactly the human-readable C++ source turns into the binary 0s and 1s that the CPU executes. The compiler doesn't directly write binary machine code into the object file in many cases - it often goes through an intermediate step: assembly language.
Assembly language is a human-readable representation of machine code. Each CPU instruction like "add two registers" or "jump to address if zero" has a textual mnemonic (like ADD or JZ) and operands (register names, immediate values, memory addresses).
Assembly is specific to the processor architecture. For example, x86-64 assembly differs from ARM assembly. However, it's much simpler than C++ as it's basically a direct mapping to machine instructions.
In many compilers, the process looks like this:
- The compiler's code generation phase writes out an assembly file, often with a
.sextension, from the C++ source. - An assembler program then reads the assembly file and produces an object file with actual machine code bytes.
This two-step approach has historical and practical reasons.
Historically, it was simpler to implement the complex high-level language translation in the compiler and then delegate the well-understood task of turning assembly into object code to an assembler.
Practically, it also allows developers to inspect the assembly output for optimization or debugging. Some compilers still make it easy to get the assembly output with a flag like -S.
Additionally, using an assembler abstracts away the details of the object file format and relocation for the compiler writers - the assembler knows how to produce a correct .o/.obj file for the platform, so the compiler can focus on generating correct assembly.
It's worth noting that not all compilers invoke a separate assembler program these days.
For instance, MSVC on Windows generates object files directly, and LLVM's back-end can directly emit machine code without writing an assembly file.
But conceptually, even in those cases, there is an "assembly generation phase" internally followed by an encoding to object file format. The result is the same: we get an object file with machine code.
Summary
Here are the key points to remember:
- Source Files, Headers, and Translation Units: C++ source files (
.cpp) are compiled separately. Each source, plus all the headers it#includes after preprocessing, form a translation unit - the basic unit of code that the compiler translates into one object file. - Preprocessing Stage: Before actual compilation, the C++ preprocessor runs. It handles macro expansions by replacing
#definedirectives, handles include directives by inserting header file contents, and handles conditional compilation by reacting to#ifdefand similar directives. The result is a single, expanded source code file - the translation unit - with no preprocessor directives left. - Compilation to Object Code: The compiler then converts the translation unit into machine code for that source file. This generates an object file (
.oon Unix,.objon Windows) containing the compiled machine code and placeholders for unresolved references. At this stage, each object file is separate and not yet a complete program. - Assembler and Machine Code Generation: Under the hood, the compiler often produces assembly language as an intermediate step. The assembler then translates this assembly code into the binary machine code inside the object file. Modern compiler toolchains perform this seamlessly, but conceptually the assembler's job is to finalize the machine instructions and package them with metadata into the object file.
Object Files and the Linking Process
The linker's role in the build process, how it resolves symbols to combine object files, and how to troubleshoot common errors.