Working with C-Style Strings
A guide to working with and manipulating C-style strings, using the <cstring> library
In this lesson, we'll focus on some helper functions that can help us work with C-style strings. In most cases, we should not use C-style strings. Even with these helper functions, they are still unpleasant to work with and have many potential pitfalls.
More modern approaches such as std::string are typically easier and safer to work with, and they come with more capabilities out of the box.
However, C-style strings remain in common use with external libraries and tools that we will integrate with. Therefore, a basic knowledge of what they are and how they work is extremely useful.
Character Arrays
In the previous lesson, we covered how C-strings (and other null-terminated strings) are stored in an array-like layout in memory. A C-style string is typically a pointer - a char* to the first character in the array:

This gives us another way to create C-style strings using C-style array syntax:
int main(){
char MyString[6]{"Hello"};
}This allows us to specify how much memory is available for the string, remembering to include space for the null terminator.
The ability to specify the size is useful if we aren't going to provide an initial value for the string, or if we're going to modify the string to be longer later in our application.
The array form of strings (char[]) and the pointer form (char*) are mostly interchangeable. This is perhaps not surprising if we recall that C-style arrays aren't that different from a pointer to the first element, and often decay to exactly that.
C-Style Arrays
A detailed guide to working with classic C-style arrays within C++, and why we should avoid them where possible
But, there are some differences. Most notably, the array form will allocate the characters onto the stack by default. We can change that in the usual ways, with the new keyword and/or smart pointers:
#include <memory>
int main(){
// Dynamic allocation of string
auto MyStringA{std::make_unique<char[]>(50)};
// Dynamic allocation of string with initial value
std::unique_ptr<char[]> MyStringB{
new char[50]("Hello")};
}The cstring Header
The standard library includes a collection of functions that can be useful for working with C-style strings.
They're available by including the <cstring> header file.
#include <cstring>The full collection of utilities available can be seen from a standard library reference, such as cppreference.com. but we'll cover the most useful ones below, alongside some issues and pitfalls to consider.
String Length using strlen()
The strlen() function returns the number of characters in a C-style string, not counting the null terminator:
#include <iostream>
#include <cstring>
int main(){
const char* MyString{"Hello"};
std::cout << "String Length: "
<< strlen(MyString);
}String Length: 5Note that when using a character array, the length of the string is not necessarily the same as the length of the array allocated to store the string.
The array may have additional space, after the string's null terminator. strlen() returns the length of the string, not the length of the array:
#include <iostream>
#include <cstring>
int main(){
char MyString[100]{"Hello"};
std::cout << "Array Length: "
<< sizeof(MyString) / sizeof(char);
std::cout << "\nString Length: "
<< strlen(MyString);
}Array Length: 100
String Length: 5Comparison using strcmp()
The strcmp() function accepts two strings as arguments. It then compares them alphabetically, ie, in dictionary order. This is also sometimes referred to as lexical order or lexicographic order.
strcmp() will return an integer, which we should interpret in the following way:
- If the integer is negative, the first string comes before the second string in the dictionary order
- If the integer is zero, the two strings are the same
- If the integer is positive, the first string comes after the second string in the dictionary order
In this example, we do a simple comparison to check if two strings are equal:
#include <cstring>
#include <iostream>
int main(){
const char* A{"Bear"};
const char* B{"Bear"};
const char* C{"Zebra"};
if (strcmp(A, B) == 0) {
std::cout << "A and B are equal";
}
if (strcmp(B, C) != 0) {
std::cout << "\nB and C are not equal\n";
}
if (strcmp(B, C) < 0) {
std::cout << B << " comes before " << C;
}
}A and B are equal
B and C are not equal
Bear comes before ZebraHere, we use the strcmp() function as a predicate for the std::ranges::sort() algorithm, to put a range of strings in alphabetical order:
#include <algorithm>
#include <cstring>
#include <iostream>
#include <vector>
int main(){
std::vector Animals{
"Bear", "Zebra", "Chicken", "Alligator"};
auto Predicate{
[](const char* A, const char* B){
return strcmp(A, B) < 0;
}
};
std::ranges::sort(Animals, Predicate);
for (const char* Animal : Animals) {
std::cout << Animal << '\n';
}
}Alligator
Bear
Chicken
ZebraWe introduced range-based algorithms and std::ranges::sort() earlier in this course:
Iterator and Range-Based Algorithms
An introduction to iterator and range-based algorithms, using examples from the standard library
Concatenation using strcat_s()
The strcat_s() function appends one C-style string onto another. Combining strings in this way is referred to as concatenation.
The function takes care of copying the characters for us and repositions the null terminator into the correct place.
However, we are responsible for ensuring the string has enough surplus memory to store what we're concatenating onto it.
#include <iostream>
#include <cstring>
int main(){
char MyString[50]{"Hello"};
strcat_s(MyString, " World");
std::cout << MyString;
}Hello WorldThe strcat_s() function is a modern alternative to the earlier strcat() function, which was deprecated for safety reasons. Specifically, it could be used in cases where the destination did not have enough memory to store everything we were concatenating.
This resulted in buffer overflow issues, where our program could corrupt the memory that falls after our string.
The original strcat() function was not doing enough to prevent this from happening, so it was replaced with the strcat_s() function.
strcat_s() includes additional checks to ensure the destination has enough space to perform the requested concatenation.
In many cases, the compiler can determine the size of the destination automatically, but not always. Given the propensity of C-style arrays to lose track of their size by decaying to a pointer, we sometimes have to intervene.
If the compiler cannot determine the size of the destination automatically, it will throw an error. We can provide the size manually using an alternative function signature, where we provide it as the second argument:
#include <iostream>
#include <memory>
#include <cstring>
int main(){
std::unique_ptr<char[]> MyString{
new char[50]("Hello")};
strcat_s(MyString.get(), 50, " World");
std::cout << MyString;
}Hello WorldAt run time, our program will check if the size is not big enough before doing the concatenation. If it isn't, our program will throw a runtime error rather than corrupting memory.
In release configurations, this check is disabled for performance reasons, but the noisy failure should be enough for us to catch the problem during the development cycle.
Copying using strcpy_s()
Creating a copy of a C-style string is not as easy as we might expect. If we create a copy in the normal way, using the = operator, what we're creating is a copy of the pointer.
int main(){
const char* Source{"Hello"};
const char* Destination{Source};
}After running this code, both Source and Dest point to the same location in memory.
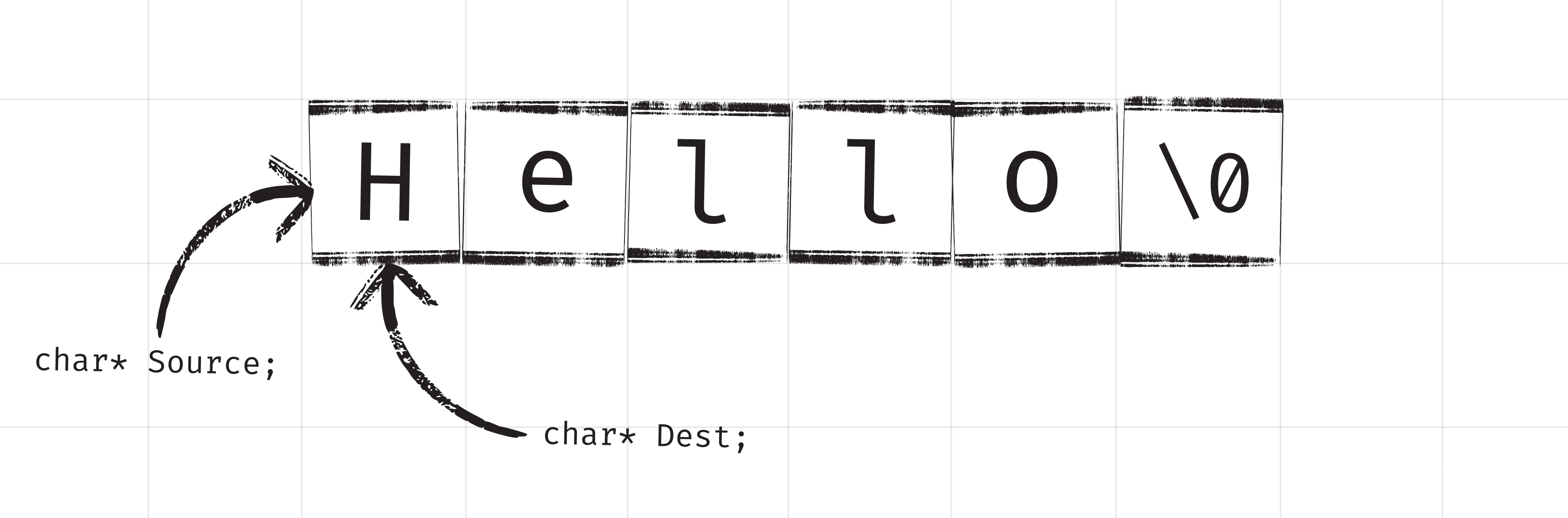
As such, modifications to one string would affect the other.
#include <iostream>
#include <cstring>
int main(){
char Source[50]{"Hello"};
const char* Copy{Source};
std::cout << "Copy Content is: " << Copy;
// We modify the source string...
strcat_s(Source, " World");
// ...but the copy will change too
std::cout << "\nCopy Content is: " << Copy;
}Copy Content is: Hello
Copy Content is: Hello WorldThis type of copy is often referred to as a shallow copy. We have multiple variables, but below the surface, those variables share one or more underlying resources.
To create a full, deep copy of the string, we first need to allocate enough space in memory for the copy. We can do this by creating a character array with enough space for the string and the null terminator.
We can then use the should use the strcpy_s() method, passing the destination first, and the source second. We are responsible for ensuring the destination has enough space for the source string, as well as the null terminator:
#include <iostream>
#include <cstring>
int main(){
char Source[50]{"Hello"};
char Dest[50];
strcpy_s(Dest, Source);
std::cout << "Dest Content: " << Dest;
// We modify the source string...
strcat_s(Source, " World");
std::cout << "\nSource Content: " << Source;
// ...but now the copy will remain the same
std::cout << "\nDest Content: " << Dest;
}Destination Content: Hello
Source Content: Hello World
Destination Content: HelloAs we can see from the output, modifications to the source string no longer affect the destination. This is because, unlike the earlier example, we are now doing a "deep copy". The entire string is copied in memory, not just the pointer:

Similar to strcat_s(), the strcpy_s() function replaces the older strcpy() function, which was deprecated due to poor protection against buffer overflows.
If the compiler believes the destination does not have enough space for the copy, it will throw an error to alert us to the danger.
If the compiler cannot determine the amount of space available at the destination, it will also throw an error. We can address this by switching to an alternative form of the strcpy_s() function, which allows us to provide the size as the second argument:
#include <iostream>
#include <cstring>
int main(){
char Source[50]{"Hello"};
auto Dest{std::make_unique<char[]>(50)};
strcpy_s(Dest.get(), 50, Source);
std::cout << "Dest Content is: " << Dest;
}Dest Content is: HelloSimilar to the strcat_s() behavior, the strcpy_s() function includes a runtime assertion that ensures this size is big enough to hold the copy. This hopefully allows us to catch any potential problems during development. In release configurations, this check is disabled to maximize performance.
Memory Corruption with strcpy(), strcat()
Even though strcpy() and strcat() have been deprecated, we may still want to use them. A likely scenario for this is if we're using an old library that hasn't been updated.
We can ask the compiler to ignore these warnings by defining _CRT_SECURE_NO_WARNINGS within our project settings, or as a #define directive that occurs before any #include directives:
#define _CRT_SECURE_NO_WARNINGS
#include <cstring>
int main(){
const char* Source{"Hello"};
char Dest[5];
strcpy(Dest, Source);
}This example has a memory corruption issue, as Dest is not big enough to store what we're trying to copy. We forgot to include space for the null terminator.
The compiler will not detect an error here. Once built in release mode, our program will corrupt memory unrelated to our string, and keep running.
The following simple program demonstrates a buffer overflow, by specifically stating what we want to be in a memory location, and then overflowing that location:
#define _CRT_SECURE_NO_WARNINGS
#include <cstring>
#include <iostream>
int main(){
char Name[5]{"Ann"};
// Storing bank balance in the memory location
// that is immediately after the string
int* Balance = reinterpret_cast<int*>
(Name + sizeof(Name));
*Balance = 500;
std::cout << "Hi " << Name <<
", your balance is $" << *Balance;
// We don't have enough space to store this string
// so it will overflow to adjacent memory
std::cout << "\nUpdating name...\n";
strcpy(Name, "Anna");
// Balance has now been corrupted
std::cout << "Hi " << Name <<
", your balance is $" << *Balance;
}Hi Ann, your balance is $500
Updating name...
Hi Anna, your balance is $256But, in real programs, the implications of memory corruption are highly variable. Each time it happens, it can look like a new bug that has never been seen before and will never be seen again.
Its effects depend on what is in the memory location that was corrupted, and that can be different every time. This is what makes memory corruption so insidious. It is something we should be aware of, and proactively be on the lookout for.
In the previous example, we're doing a few things that are considered bad practices. Modern C++ gives us many better options that make bugs like this much more difficult to introduce. One of those options is a much better implementation of strings the std::string object.
Previously, we've been using std::string where possible. We'll go back to that convention in the next lesson, where we dive a bit deeper into how std::string works, and the powers it gives us.
Summary
In this lesson, we've explored working with C-style strings in C++, focusing on how to manipulate them safely using functions from the <cstring> library.
We've emphasized the transition from older, less secure functions to their safer counterparts and highlighted best practices to avoid pitfalls associated with manual memory management.
Main Points Learned
- C-style strings are stored as null-terminated character arrays and can be manipulated using the
<cstring>library. - The
strlen()function is used to find the length of a C-style string, excluding the null terminator. strcmp()allows for lexicographical comparison of two strings, returning an integer to indicate their relational order.strcat_s()andstrcpy_s()are safer alternatives tostrcat()andstrcpy(), designed to prevent buffer overflow by ensuring sufficient memory space.- Memory corruption and buffer overflow issues can arise from improper use of C-style strings
A Deeper Look at the std::string Class
A detailed guide to std::string, covering the most essential methods and operators